Что такое веб-архивы в интернете и как они помогают восстанавливать сайты

Открыли нужную страницу, но видите сообщение, что ее больше нет? Спокойно, без паники, пропавший контент всё еще можно восстановить. Для этого нужно немного: вернуться в прошлое. А сделать это нам помогают веб-архивы.
 Что такое веб-архивы
Что такое веб-архивыРедакция MC.today разобралась, что такое веб-архивы, какие актуальные ресурсы есть в интернете и для чего их используют.
Содержание
- Что такое веб-архивы?
- История появления
- Назначение веб-архивов
- Веб-архивы против «вымирания» ссылок
- Действующие веб-архивы
- web.archive.org
- archive.today
- Что делать, если страницу удалили и ее нет ни в одном из архивов?
- Как скачать сайт из веб-архива?
- Как узнать все страницы сайта в веб-архиве?
- Как запретить добавление сайта в веб-архив
Что такое веб-архивы?
Веб-архив – это сервис, который собирает и сберегает копии сайтов. При этом для каждого сайта сохраняется не одна, а множество, иногда тысячи, версий за разные даты.

Что такое веб-архив
Благодаря этому можно проследить историю изменения сайта с момента возникновения, найти информацию, которую удалили, и даже восстановить свой сайт, когда нет резервной копии.
История появления
С древнейших времен люди пытались сохранить и передать потомкам накопленные знания. В III веке до нашей эры крупнейшим в мире собранием научных трудов стала Александрийская библиотека в Египте. А в 1996 году американский инженер Брюстер Кейл назвал в честь нее свою коммерческую систему веб-архивирования Alexa Internet.
Подобно Александрийской библиотеке, Alexa собирала информацию, но уже в сети Интернет. С помощью фирменной панели инструментов пользователь мог получить данные о каждом посещенном сайте: имена владельцев, количество страниц, как часто сайт обновляется и много ли на него ссылок в других ресурсах.

Wayback Machine
Позже помимо сканирования, специальные поисковые роботы компании стали архивировать веб-страницы. Эту информацию нужно было как-то систематизировать. Так в 2001 году появился Wayback Machine, или цифровой архив Всемирной паутины, в котором сегодня насчитывают более 740 млрд веб-страниц.
Назначение веб-архивов
Изначальной целью проекта, по словам его создателей, был «универсальный доступ ко всем знаниям» путем сохранения архивных копий страниц. Но, как и всякое дальновидное начинание, веб-архив показал, что его предназначение не ограничивается только этим. Вот что сегодня можно сделать с его помощью.
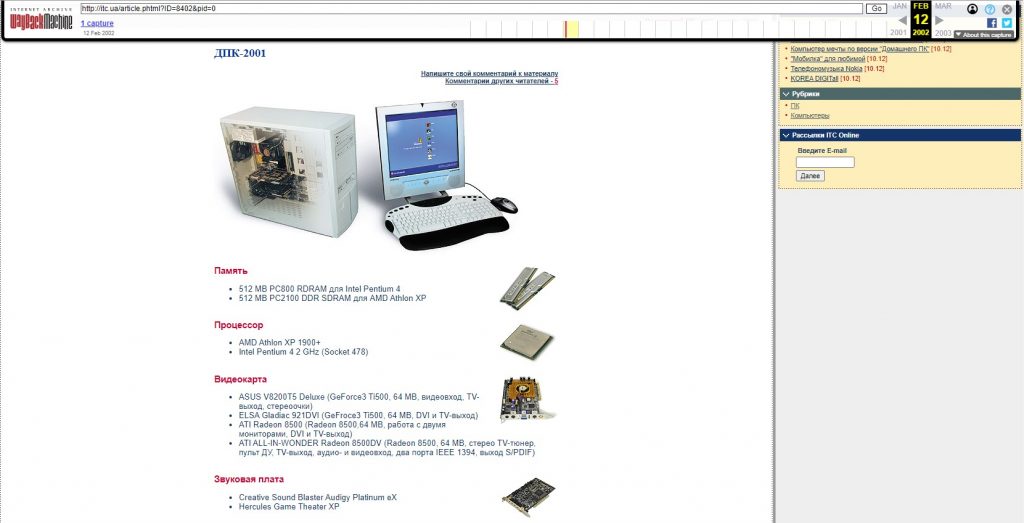
- Ввести в строку поиска название любимого сайта, чтобы просмотреть, как он выглядел 5, 10 или даже 20 лет назад. Узнать о чём тогда писали газеты, что обещали политики и какой, например, процессор знатоки советовали ставить в «ПК месяца» за 2001 год.

Рубрика «ПК месяца» на сайте itc.ua за 2001 год
- Восстановить резервную копию своего сайта. Правда сделать это вручную будет довольно сложно, так как ссылок могут быть тысячи. Поэтому лучше использовать парсер – специальный сервис, который автоматизирует процесс сбора информации в архиве.
- Маркетологи и специалисты по СЕО могут проанализировать изменение интересных им сайтов за определенный период.
- Журналисты и все любопытные граждане могут найти уникальную информацию, которую удалили, например, в результате цензуры.
- Покупатели доменов могут проверить перед покупкой их историю, чтобы убедиться, что прежние владельцы не публиковали сомнительный контент.
Веб-архивы против «вымирания» ссылок
На фоне борьбы с дезинформацией в интернете стала актуальной проблема «вымирания» ссылок. И, как оказалось, без веб-архива тут тоже никак. Дело в том, что жизнь многих веб-страниц длится недолго. Причины этому могут быть самыми разными. Иногда владельцы сайтов забывают продлить хостинг, просто не заинтересованы в дальнейшей поддержке своих проектов или удаляют статьи, чтобы заменить их новыми. Бывает, что битые ссылки появляются в результате технических неполадок или изменения файловой структуры.
Согласно исследованию The New York Times, более четверти всех ссылок, когда-либо появлявшихся на страницах онлайн-версии издания, сегодня неактивны. А для публикаций за 1998 год эта цифра и вовсе составляет колоссальные 72%.
Вы скажете: «Подумаешь, одни ссылки пропали, другие появились, а в целом ничего не изменилось». Но ситуация хуже, чем может показаться на первый взгляд, и касается всех нас. Судите сами: с помощью этих ссылок сайты могут нести ценную научную информацию или доказывать какие-то спорные утверждения. А потом всё исчезает в одну ночь.
В лучшем случае ссылка становится недоступной. В худшем – такие мертвые ссылки находят злоумышленники, выкупают домен для себя и подменяют первоначальный вариант статьи выгодной им дезинформацией. Поэтому, например, Википедия убедительно просит своих авторов подкреплять цитаты ссылкой на страницы из архива Wayback Machine, где их никто не сможет изменить.
Действующие веб-архивы
На сегодня веб-архив, который основал Брюстер Кейл, остается старейшим и самым полным собранием архивных копий сайтов. Но кроме него есть и другие, которые отличаются перечнем доступных ресурсов, дополнительными функциями, но призваны решать ту же задачу.
- Web.archive.org – самый старый и самый полный из всех архивов. Копии страниц с 1998 по 2012 год можно найти только тут.
- Archive.today – начал работу в 2012 году. В отличие от Wayback Machine не использует поисковых роботов и архивирует страницы только по запросу пользователей. Имеет несколько зеркал: archive.is, archive.li, archive.ph, archive.fo и другие.
- Perma.cc – некоммерческий сервис по архивированию интернет-источников, цитируемых в научных работах.
- Webcite – открылся в 2003 году и обрабатывал запросы только на сохранение отдельных страниц. В данный момент сервис свернул работу и не принимает новых заявок, но всё еще продолжает обслуживать созданные архивы.
- Web-arhive.ru – образец того, так хорошая идея может порой трансформироваться до неузнаваемости. Основное направление сервиса – создание заверенных копий сайтов, социальных сетей и переписки для использования в суде.
web.archive.org
Рассмотрим возможности сервиса подробнее. На главной странице мы видим форму для поиска. В нее можно вставить адрес любого интересного вам сайта и нажать «Ввод». После это этого архив сформирует календарь, в котором представлены все сохраненные копии ресурса от самой старой до наиболее актуальной.
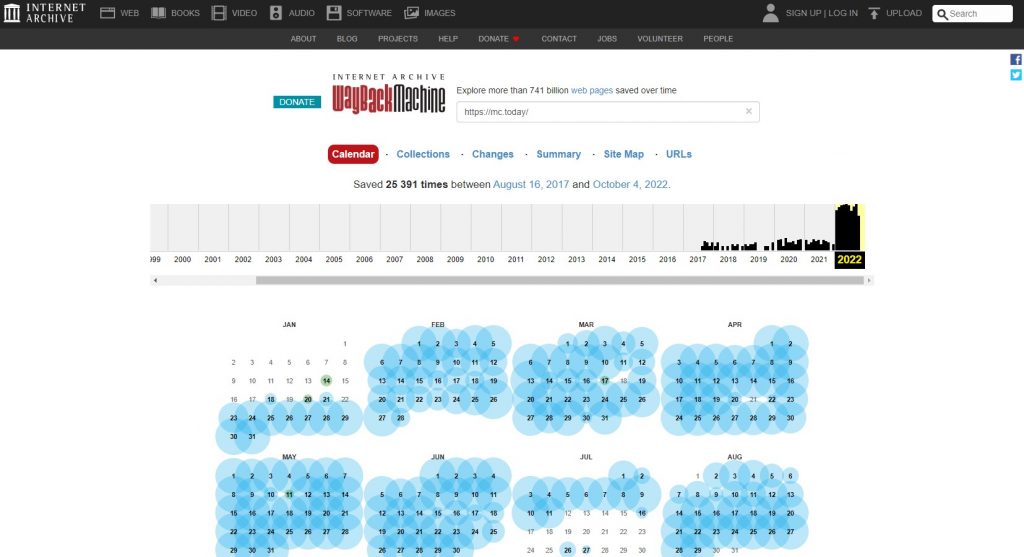
Архивные копии сайта MC.today за 2022 год
Как видим, в 2022 году копии сайта MC.today сохраняются каждый день. Но если вернуться в 2018 год, то их уже намного меньше. Цвет и размер точек, которыми обозначены сохранения, имеет значение. Чем больше диаметр точки, тем больше копий сайта было сделано в этот день. Голубой и зеленый цвета говорят, что архивация прошла успешно. Оранжевый указывает на допущенные при архивации ошибки. Красный означает, что ошибки были критическими.
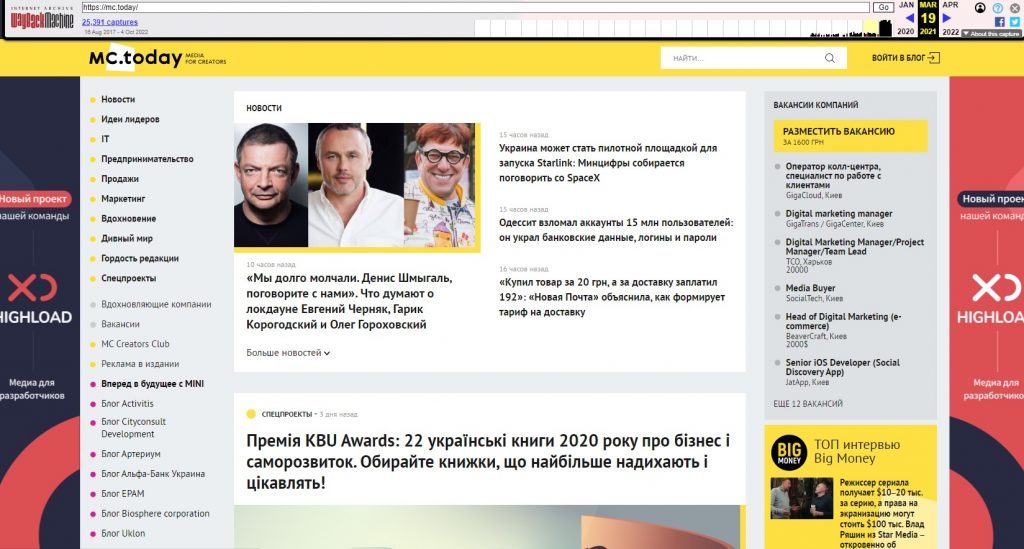
Копия главной страницы сайта MC.today за 19 марта 2021 года
Отсюда ясно, что для просмотра лучше всего выбирать голубые точки. Выберем для нашего сайта одну из них, например, за 19 марта 2021 года. При клике по выбранной ссылке откроется страница сайта, какой она была в то время. При этом все ссылки будут активными. По ним можно перейти к одной из статей или выбрать другую дату, чтобы продолжить просмотр.
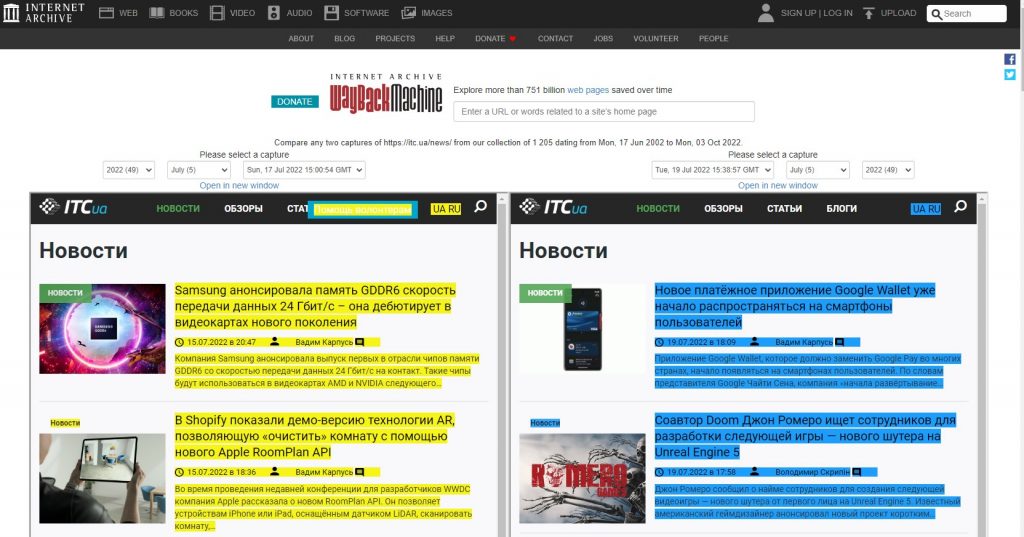
Инструмент Changes
Посмотреть изменения в содержимом заархивированных страниц позволяет инструмент Changes. Выберите две даты для сравнения и нажмите кнопку Compare. Сервис отобразит на экране оба варианта страницы и выделит желтым цветом удаленный, а голубым – добавленный контент.
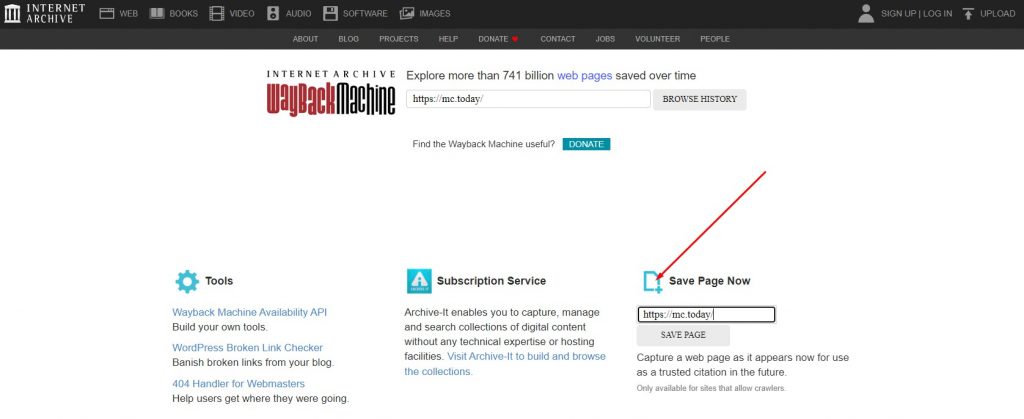
Вкладка Save Page Now
Чтобы сохранить текущую версию сайта в веб-архиве, найдите на его главной странице вкладку Save Page Now. Затем введите ссылку и нажмите «Сохранить страницу». Подобную процедуру советуют выполнять перед всеми серьезными изменениями сайта. Тогда даже в случае утраты резервной копии восстановить сайт можно будет из веб-архива.
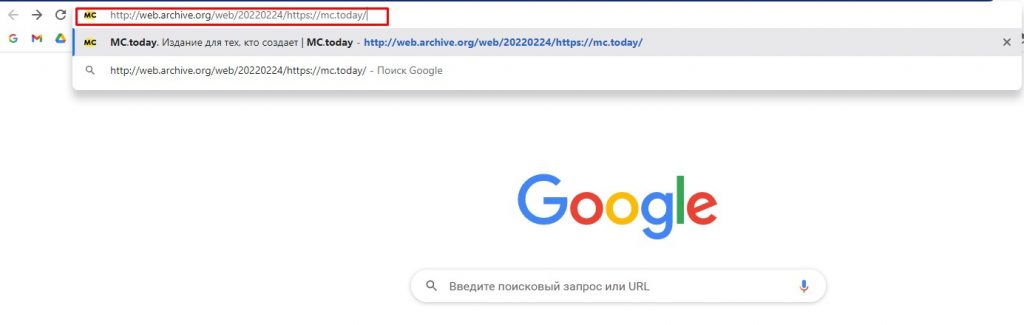
Как посмотреть архивную копию страницы за определенную дату
Если место адреса страницы ввести поисковый запрос, то сервис выдаст всё, что по этой теме есть в сохраненных сайтах. Есть также возможность посмотреть архивную копию страницы за определенную дату. Для этого введите в адресную строку конструкцию типа http://web.archive.org/web/20220224/https://mc.today/, где 20220224 – год, месяц и день, а mc.today можно заменить на адрес нужного вам сайта.
archive.today
На главной странице выделяются две ярких формы. Верхняя красная позволяет архивировать страницу. Нижняя серая помогает найти сайт среди уже сохраненных. Например, для сайта pravda.com.ua сервис нашел более 157 сохранений с 2017 до 2022 года и около 50 более старых, начиная с 2012 года.
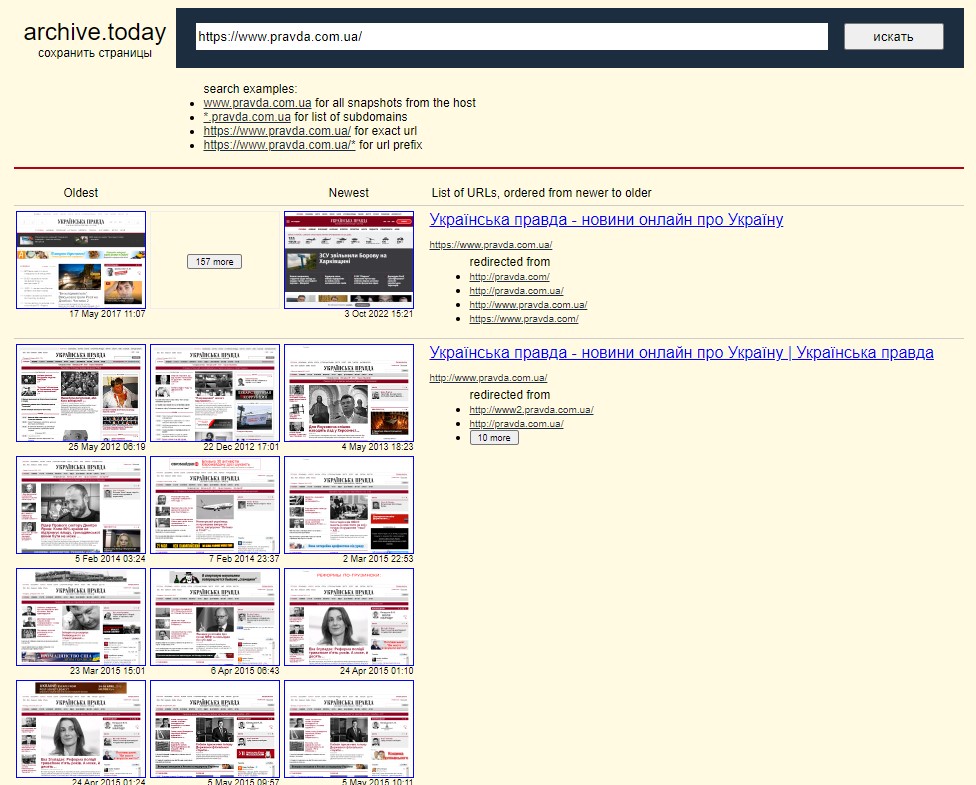
Пример работы сервиса archive.ph
Интересно, что archive.ph игнорирует стандартный запрет доступа для поисковых роботов с помощью файла robots.txt. За счет этого в его поиске можно обнаружить и те сайты, владельцы которых запретили архивацию.
Что делать, если страницу удалили и ее нет ни в одном из архивов?
Возможно страницу удалили раньше, чем она смогла попасть в веб-архив. Но вариантны всё равно есть. Во-первых, нужно поискать в кэше Google. Для этого нужно ввести в адресную строку ссылку типа cache:URL, где URL – адрес страницы, которая вам нужна. Например, cache:https://mc.today/uk/.
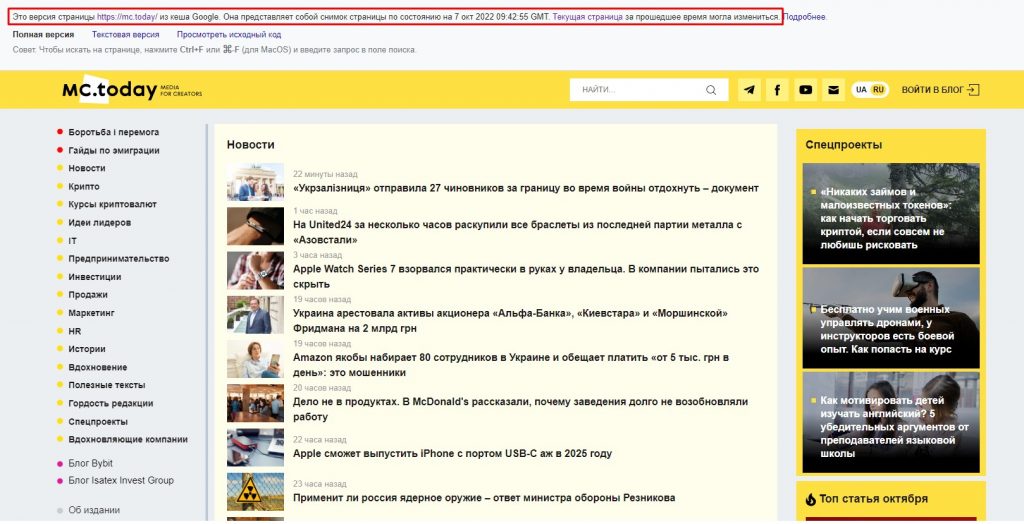
Поиск в кэше Google
В моем случае над копией страницы появилась надпись: «Это версия страницы https://mc.today/ из кеша Google. Она представляет собой снимок страницы по состоянию на 7 окт. 2022 09:42:55 GMT». Ссылки на сохраненные страницы можно найти и в простой поисковой выдаче. Для этого нужно нажать на треугольник рядом с адресом страницы и выбрать пункт «Кэш».
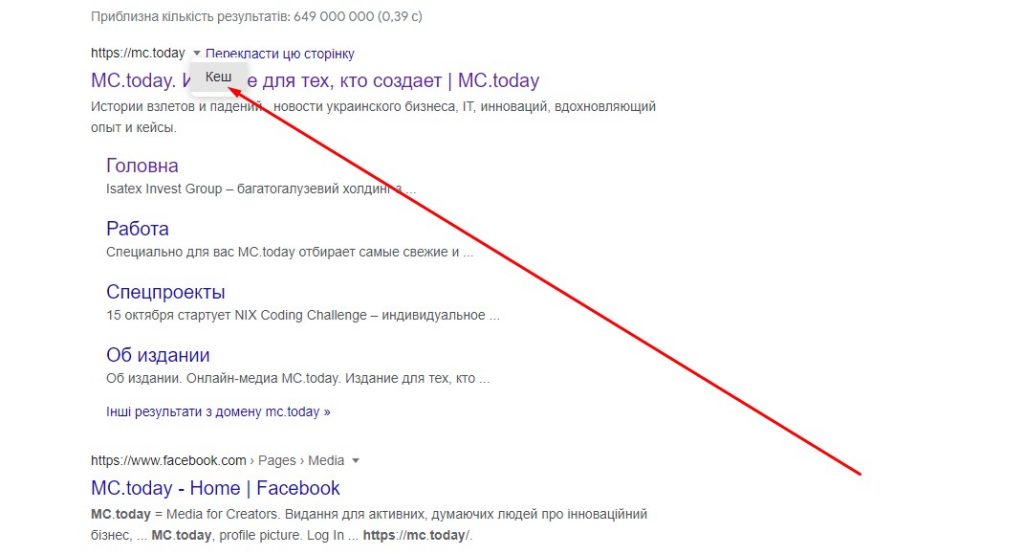
Как выбрать пункт «Кэш» в результатах поиска
Однако следует понимать, что в кэше хранится только самая актуальная копия каждой страницы. При каждом обходе поискового робота он перезаписывает ее на новую, а старые версии удаляет. Определить частоту обновления кэша в Google довольно сложно. Она может варьироваться от 1 до 15 дней. Но известно, что Яндекс и китайский поисковик Baidu обновляют кэш 1–2 раза в неделю. Значит, если страницу удалили пару дней назад, то шансы найти ее в кэше одной из поисковых систем всё еще велики.
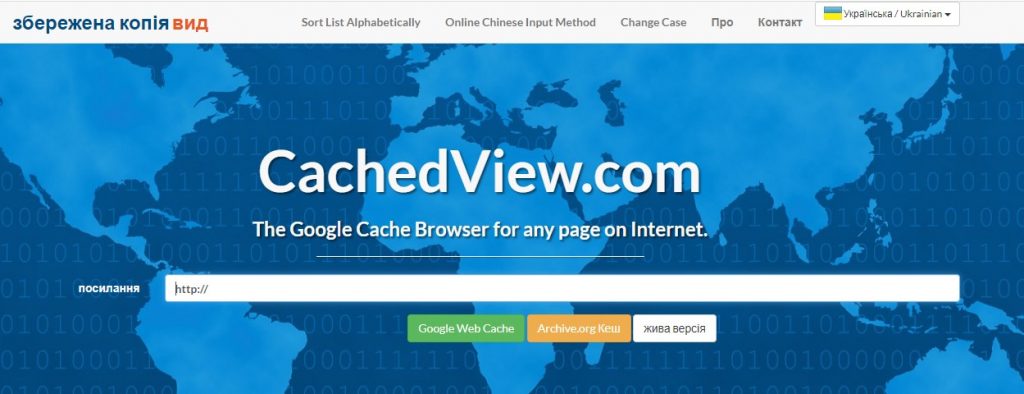
Главная страница сайта CachedView.com
Чтобы не перебирать все их по очереди, пользуйтесь специализированным сервисом CachedView.com. Он позволяет одновременный поиск по кэшу Google и Archive.org, а также системе распространения контента Coral Cache. Аналогичный функционал имеет поисковик http://www.cachedpages.com/.
Как скачать сайт из веб-архива?
Мы уже разобрались, как найти архив сайта при помощи Wayback Machine. Но страниц на сайте, как правило, слишком много, чтобы скачать все их вручную. К тому же набор разрозненных файлов не поместишь на сервер. Для начала нужно восстановить структуру папок и ссылок исходного сайта. Всё это без труда сделает программа Wayback Machine Downloader.
Итогом ее работы будет папка вида /websites/example.com с последними сохраненными версиями каждого файла и страницей index.html. Затем ее можно поместить на сервер, чтобы запустить копию сайта. Иногда требуется скачать не весь сайт, а только какую-то его часть с изменениями за всё время. С этим поможет инструмент Waybackpack.
Как узнать все страницы сайта в веб-архиве?
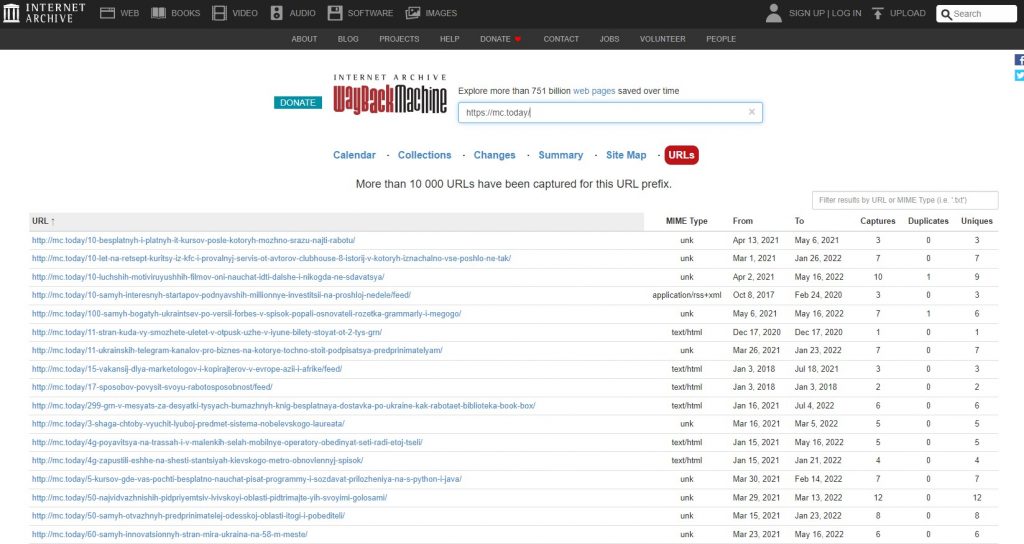
Список всех заархивированных страниц сайта
Wayback Machine позволяет получить список всех заархивированных страниц сайта. Для этого нужно ввести в адресной строке https://web.archive.org/web/*/[URL]/*. На примере нашего сайта видно, что архив выдал больше десяти тысяч ссылок, которые можно дополнительно отфильтровать по ключевым словам и типу.
Как запретить добавление сайта в веб-архив
Не все владельцы сайтов хотят, чтобы их проекты сохранялись в Wayback Machine. Одни опасаются за свой уникальный контент и не хотят, чтобы кто-то его использовал в случае удаления сайта. И эти опасения действительно имеют под собой почву. Ведь в Сети полно инструкций, как без особых затрат пополнить содержание своего сайта полезным контентом с закрытых ресурсов.
Другие собираются продавать домен и не заинтересованы, чтобы его содержание связывали с новыми владельцами, или хотят таким образом защитить личную информацию. В любом случае добавление сайта в архив можно запретить.
Проще всего это сделать через изменение настроек файла robots.txt, который блокирует доступ к сайту для поисковых роботов. В результате запрета роботы перестанут сканировать сайт, и новые страницы с него архивироваться не будут. Но собранная ранее информация всё еще останется доступной.
Чтобы ее удалить, достаточно отправить запрос на почту info@archive.org. Важно также, чтобы письмо было отправлено с почты в домене вашего сайта. Обычно вопрос решается в течение трех дней и сайт полностью исчезает из архива. Аналогичным образом ресурс можно восстановить в Wayback Machine.
Итак, веб-архив – это бесплатный проект, цель которого собрать и сохранить весь доступный в интернете контент. С помощью инструмента Wayback Machine в архиве интернета легко найти копии интересного вам сайта за выбранную дату, что может пригодиться в самых разных ситуациях. Например, позволит восстановить страницы после хакерской атаки, проанализировать изменения проекта или просто узнать о чём любимый сайт писал 20 лет назад.






Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: