Що таке веб архіви в інтернеті та як вони допомагають відновлювати сайти

Відкрили потрібну сторінку, але бачите повідомлення, що її більше нема? Спокійно, без паніки, зниклий контент все ще можна відновити. Для цього потрібно небагато: повернутися в минуле. А зробити це нам допомагають веб-архіви.
 Что такое веб-архивы
Что такое веб-архивыРедакція MC.today розібралася, що таке веб-архіви, які актуальні ресурси є в інтернеті та для чого їх використовують.
Зміст
- Що таке веб-архіви?
- Історія появи
- Призначення веб-архівів
- Веб-архіви проти «вимирання» посилань
- Діючі веб-архіви
- web.archive.org
- archive.today
- Що робити, якщо сторінку видалили і її немає в жодному архіві?
- Як завантажити сайт із веб-архіву?
- Як дізнатися всі сторінки сайту у веб-архіві?
- Як заборонити додавання сайту до веб-архіву
Що таке веб-архіви?
Веб-архів – це сервіс, який збирає та зберігає копії сайтів. При цьому для кожного сайту зберігається не одна, а іноді тисячі версій за різні дати.

Що таке веб-архів
Завдяки цьому можна простежити історію зміни сайту з моменту виникнення, знайти інформацію, яку видалили, і навіть відновити свій сайт, коли немає резервної копії.
Історія появи
З давніх-давен люди намагалися зберегти і передати нащадкам накопичені знання. У ІІІ столітті до нашої ери найбільшим у світі зібранням наукових праць стала Олександрійська бібліотека в Єгипті. А 1996 року американський інженер Брюстер Кейл назвав на честь неї свою комерційну систему веб-архівування Alexa Internet .
Подібно до Олександрійської бібліотеки, Alexa збирала інформацію, але вже в мережі Інтернет. За допомогою фірмової панелі інструментів користувач міг отримати дані про кожен відвіданий сайт: імена власників, кількість сторінок, як часто сайт оновлюється і чи багато посилань на нього в інших ресурсах.

Wayback Machine
Пізніше, крім сканування, спеціальні пошукові роботи компанії стали архівувати веб-сторінки. Цю інформацію слід було якось систематизувати. Так у 2001 році з’явився Wayback Machine, або цифровий архів Всесвітньої павутини, в якому сьогодні налічують понад 740 млрд веб-сторінок.
Призначення веб-архівів
Спочатку призначенням проекту, за словами його творців, був «універсальний доступ до всіх знань» шляхом збереження архівних копій сторінок . Але, як і будь-яке далекоглядне починання, веб-архів показав, що його призначення не обмежується лише цим. Ось що сьогодні можна зробити за його допомогою.
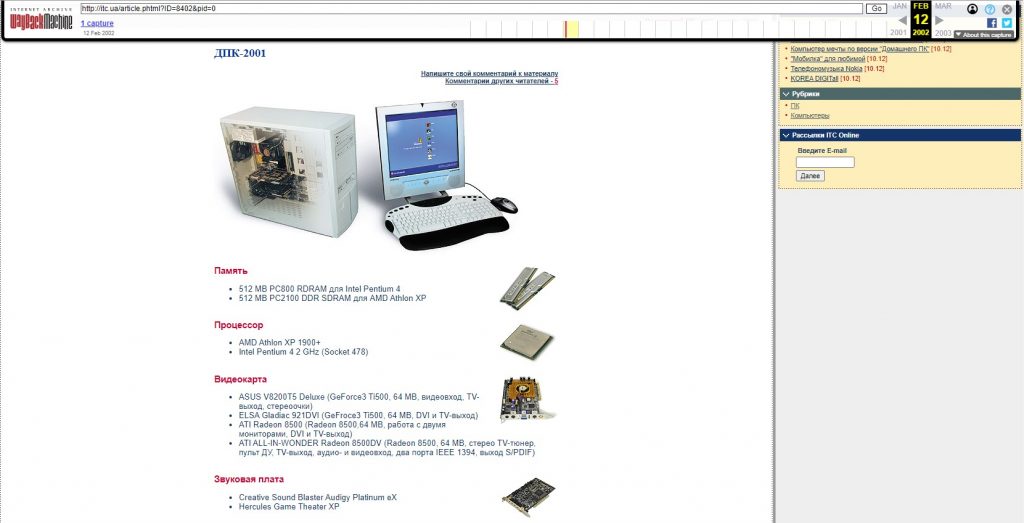
- Введіть у рядок пошуку назву улюбленого сайту, щоб переглянути, як він виглядав 5, 10 або навіть 20 років тому. Дізнайтеся, про що тоді писали газети, що обіцяли політики і який, наприклад, процесор знавці радили ставити в «ПК місяця» за 2001 рік.

Рубрика «ПК місяця» на сайті itc.ua за 2001 рік
- Відновити резервну копію сайту. Щоправда, зробити це вручну буде досить складно, оскільки посилань можуть бути тисячі. Тому краще використовувати парсер – спеціальний сервіс, який автоматизує процес збирання інформації в архіві.
- Маркетологи та фахівці з СЕО можуть проаналізувати зміну цікавих їм сайтів за певний період.
- Журналісти та всі цікаві громадяни можуть знайти унікальну інформацію, яку видалили, наприклад, у результаті цензури.
- Покупці доменів можуть перевірити перед покупкою їхню історію, щоб переконатися, що колишні власники не публікували сумнівний контент.
Веб-архіви проти «вимирання» посилань
На тлі боротьби з дезінформацією в інтернеті стала актуальною проблема вимирання посилань. І, як виявилося, без веб-архіву тут також ніяк. Справа в тому, що життя багатьох веб-сторінок триває недовго. Причини цього можуть бути різними. Іноді власники сайтів забувають продовжити хостинг, просто не зацікавлені у подальшій підтримці своїх проектів або видаляють статті, щоб замінити їх на нові. Буває, що биті посилання з’являються внаслідок технічних неполадок чи зміни файлової структури.
Згідно з дослідженням The New York Times, понад чверть усіх посилань, що коли-небудь з’являлися на сторінках онлайн-версії видання, сьогодні неактивні. А для публікацій за 1998 рік ця цифра взагалі становить колосальні 72%.
Ви скажете: “Подумаєш, одні посилання зникли, інші з’явилися, а в цілому нічого не змінилося” . Але ситуація гірша, ніж може здатися на перший погляд, і стосується всіх нас. Міркуйте самі: за допомогою цих посилань сайти можуть нести цінну наукову інформацію або доводити якісь спірні твердження. А потім все зникає в одну ніч.
У кращому випадку посилання стає недоступним. У гіршому – такі мертві посилання знаходять зловмисники, викуповують домен собі і заміняють початковий варіант статті вигідною їм дезінформацією. Тому, наприклад, Вікіпедія переконливо просить своїх авторів підкріплювати цитати посиланням на сторінки архіву Wayback Machine, де їх ніхто не зможе змінити.
Діючі веб-архіви
На сьогодні веб-архів, який заснував Брюстер Кейл, залишається найстарішим і найповнішим зібранням архівних копій сайтів. Але крім нього є інші, які відрізняються переліком доступних ресурсів, додатковими функціями, але покликані вирішувати те саме завдання.
- Web.archive.org – найстаріший і найповніший з усіх архівів. Копії сторінок з 1998 до 2012 року можна знайти тільки тут.
- Archive.today – розпочав роботу у 2012 році. На відміну від Wayback Machine, не використовує пошукових роботів і архівує сторінки лише за запитом користувачів. Має кілька дзеркал: archive.is, archive.li, archive.ph, archive.fo та інші.
- Perma.cc – некомерційний сервіс з архівування інтернет-джерел, цитованих у наукових працях.
- Webcite – відкрився у 2003 році та обробляв запити лише на збереження окремих сторінок. На даний момент сервіс згорнув роботу і не приймає нових заявок, але все ще продовжує обслуговувати створені архіви.
- Web-arhive.ru – приклад того, так хороша ідея може часом трансформуватися до невпізнанності. Основний напрямок сервісу – створення завірених копій сайтів, соціальних мереж та листування для використання у суді.
web.archive.org
Розглянемо можливості сервісу докладніше. На головній сторінці ми бачимо форму пошуку. У неї можна вставити адресу будь-якого цікавого вам сайту та натиснути «Введення» . Після цього архів сформує календар, в якому представлені всі збережені копії ресурсу від найстарішої до найактуальнішої.
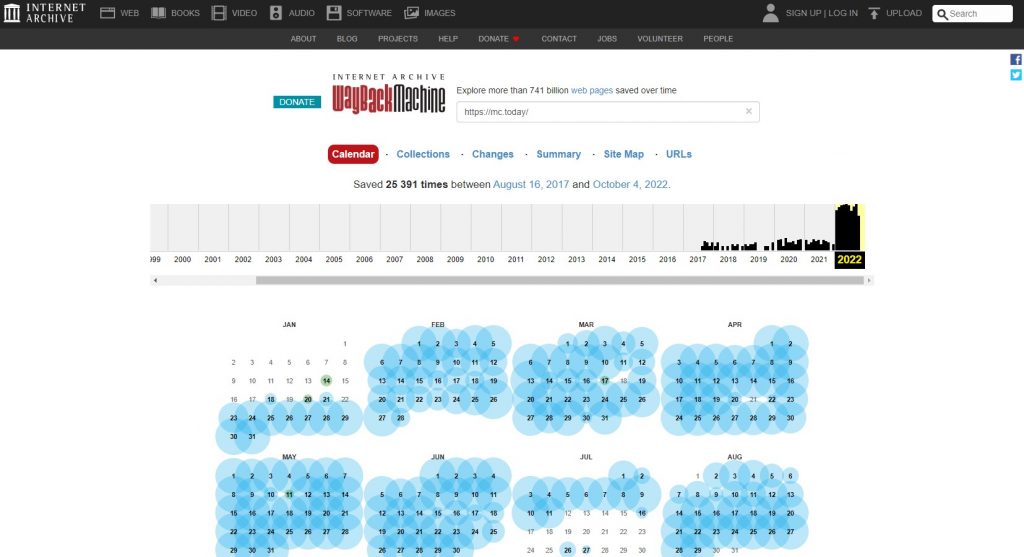
Архівні копії сайту MC.today за 2022 рік
Як бачимо, у 2022 році копії сайту MC.today зберігаються майже щодня. Але якщо повернутися у 2018 рік, то їх уже набагато менше. Колір та розмір точок, якими позначені збереження, має значення. Чим більший діаметр точки, тим більше копій сайту було зроблено цього дня. Блакитний та зелений кольори кажуть, що архівація пройшла успішно. Помаранчевий свідчить про допущені при архівації помилки. Червоний означає, що помилки були критичними.
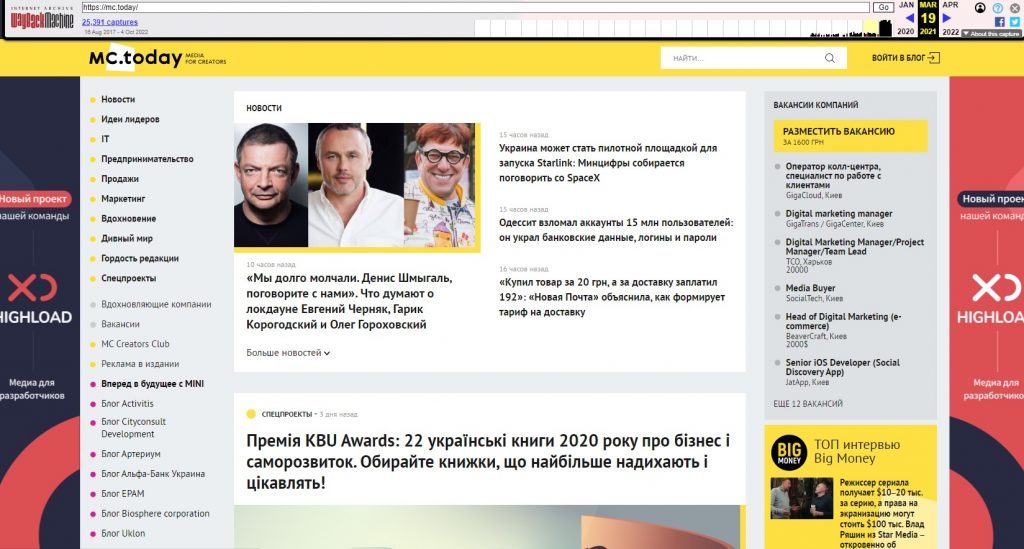
Копія головної сторінки сайту MC.today за 19 березня 2021 року
Звідси зрозуміло, що для перегляду краще вибирати блакитні точки. Виберемо для нашого сайту одну з них, наприклад, за 19 березня 2021 року. При натисканні на обране посилання відкриється сторінка сайту, якою вона була на той час. При цьому всі посилання будуть активними. Ви можете перейти по одному з них або вибрати іншу дату щоб продовжити перегляд.
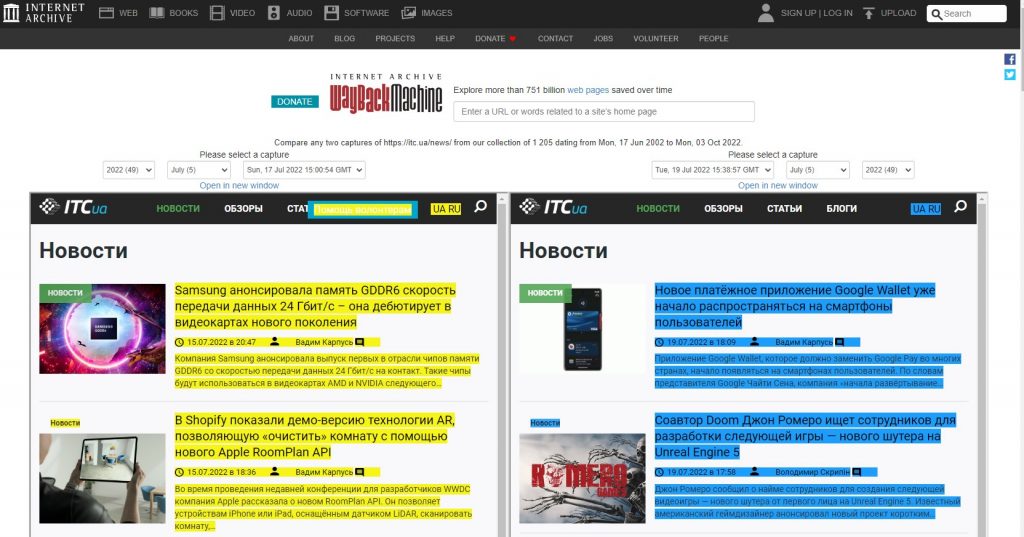
Інструмент Changes
Переглянути зміни у вмісті заархівованих сторінок дозволяє інструмент Changes . Виберіть дві дати для порівняння та натисніть кнопку Compare . Сервіс відобразить на екрані обидва варіанти сторінки і виділить жовтим віддалений, а блакитним – доданий контент.
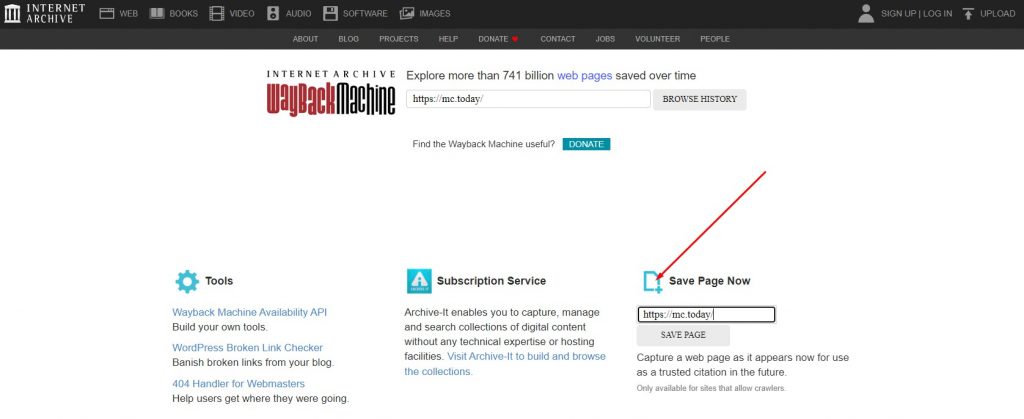
Вкладка Save Page Now
Щоб зберегти поточну версію сайту у веб-архіві, знайдіть на його головній сторінці вкладку Save Page Now . Потім введіть посилання та натисніть «Зберегти сторінку» . Подібну процедуру радять виконувати перед усіма серйозними змінами сайту. Тоді навіть у разі втрати резервної копії відновити веб-сайт можна буде з веб-архіву.
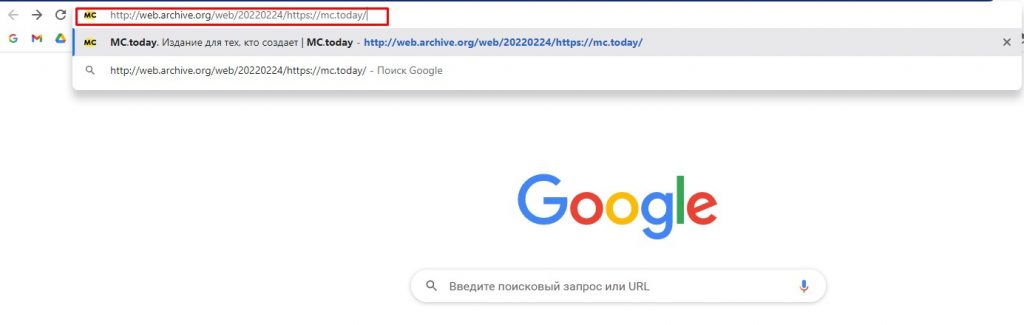
Як переглянути архівну копію сторінки за певну дату
Якщо місце адреси сторінки ввести пошуковий запит, то сервіс видасть все, що на цій темі є в збережених сайтах. Є також можливість переглянути архівну копію сторінки за певну дату. Для цього введіть в адресний рядок конструкцію типу http://web.archive.org/web/20220224/https://mc.today/, де 20220224 – рік, місяць і день, а mc.today можна замінити на адресу потрібного вам сайту.
archive.today
На головній сторінці виділяються дві яскраві форми. Верхня дозволяє архівувати сторінку. Нижня допомагає знайти сайт серед збережених. Наприклад, для сайту pravda.com.ua сервіс знайшов понад 157 збережень з 2017 до 2022 року та близько 50 старіших, починаючи з 2012 року.
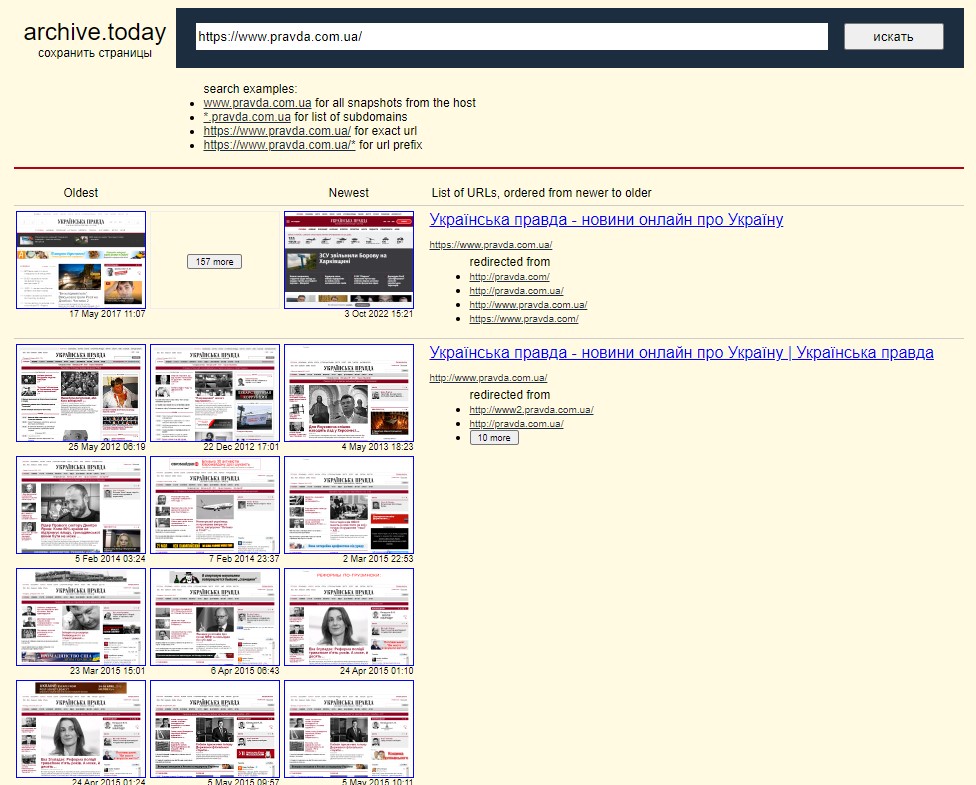
Приклад роботи сервісу archive.ph
Цікаво, що archive.ph ігнорує стандартну заборону доступу для пошукових роботів за допомогою файлу robots.txt . За рахунок цього в його пошуку можна знайти й ті сайти, власники яких заборонили архівацію.
Що робити, якщо сторінку видалили і її немає в жодному архіві?
Можливо, сторінку видалили раніше, ніж вона змогла потрапити до веб-архіву. Але варіантні все одно є. По-перше, потрібно пошукати у кеші Google. Для цього потрібно ввести в адресний рядок посилання типу cache: URL , де URL – адреса сторінки, яка вам потрібна. Наприклад, cache:https://mc.today/uk/ .
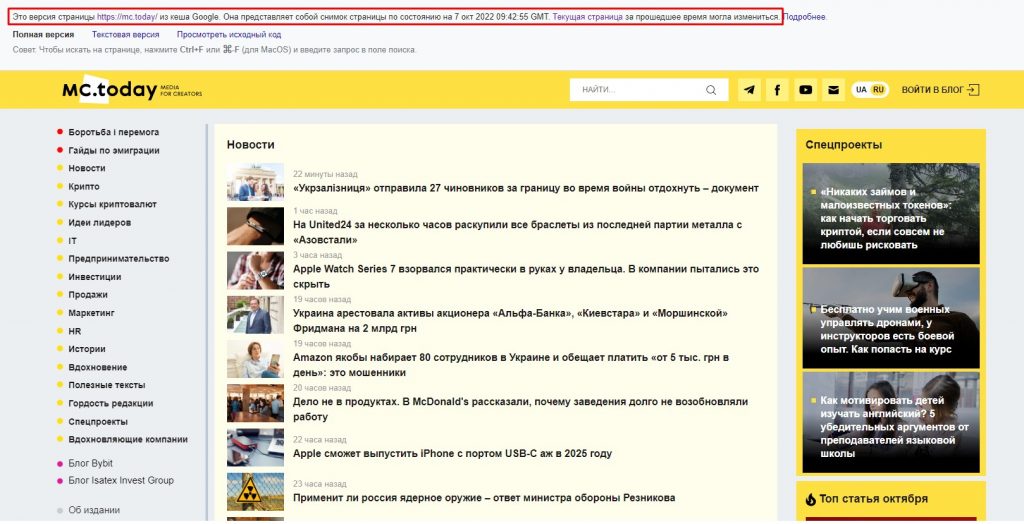
Пошук у кеші Google
У моєму випадку над копією сторінки з’явився напис: Це версія сторінки https://mc.today/ з кеша Google. Вона являє собою знімок сторінки станом на 7 жовт. 2022 09:42:55 GMT» . Посилання на збережені в кеші сторінки можна також знайти у простій пошуковій видачі. Для цього потрібно натиснути на трикутник поряд з адресою сторінки та вибрати «Кеш» .
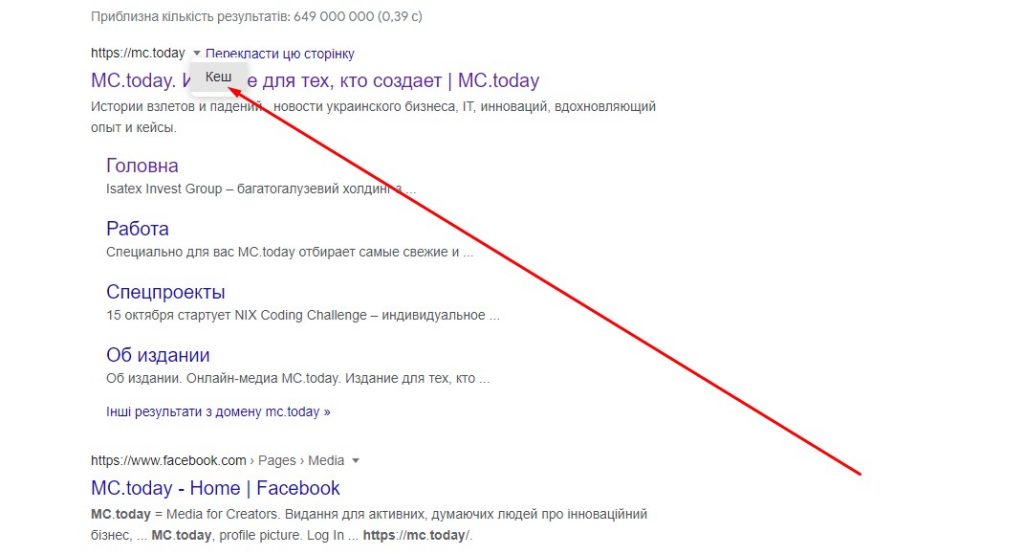
Як вибрати пункт «Кеш» у результатах пошуку
Однак слід розуміти, що в кеші зберігається лише актуальна копія кожної сторінки. При кожному обході пошукового робота перезаписує її на нову, а старі версії видаляє. Визначити частоту поновлення кешу в Google досить складно. Вона може змінюватись від 1 до 15 днів. Але відомо, що Яндекс і китайська пошукова система Baidu оновлюють кеш 1–2 рази на тиждень. Отже, якщо сторінку видалили кілька днів тому, то шанси знайти її в кеші однієї з пошукових систем все ще є.
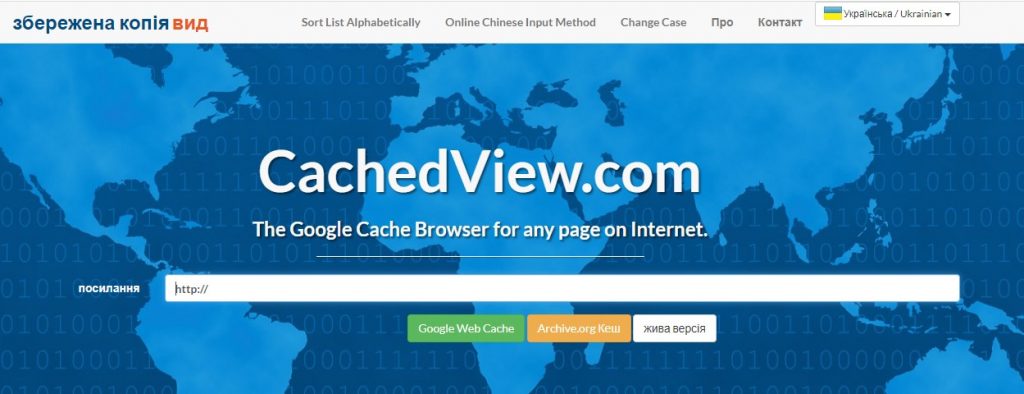
Головна сторінка сайту CachedView.com
Щоб не перебирати всі пошукові системи по черзі, користуйтеся спеціалізованим сервісом CachedView.com . Він дозволяє одночасний пошук по кешу Google та Archive.org , а також системі поширення контенту Coral Cache . Аналогічний функціонал має пошуковик http://www.cachedpages.com/.
Як завантажити сайт із веб-архіву?
Ми вже розібралися, як знайти архів сайту за допомогою Wayback Machine. Але сторінок на сайті, як правило, занадто багато, щоб завантажити всі їх вручну. До того ж, набір розрізнених файлів не помістиш на сервер. Для початку потрібно відновити структуру папок та посилань вихідного сайту. Все це легко зробить програма Wayback Machine Downloader .
Підсумком її роботи буде папка виду /websites/example.com з останніми збереженими версіями кожного файлу та сторінкою index.html. Потім її можна розмістити на сервер, щоб запустити копію сайту. Іноді потрібно завантажити не весь сайт, а лише якусь його частину із змінами за весь час. Із цим допоможе інструмент Waybackpack.
Як дізнатися всі сторінки сайту у веб-архіві?
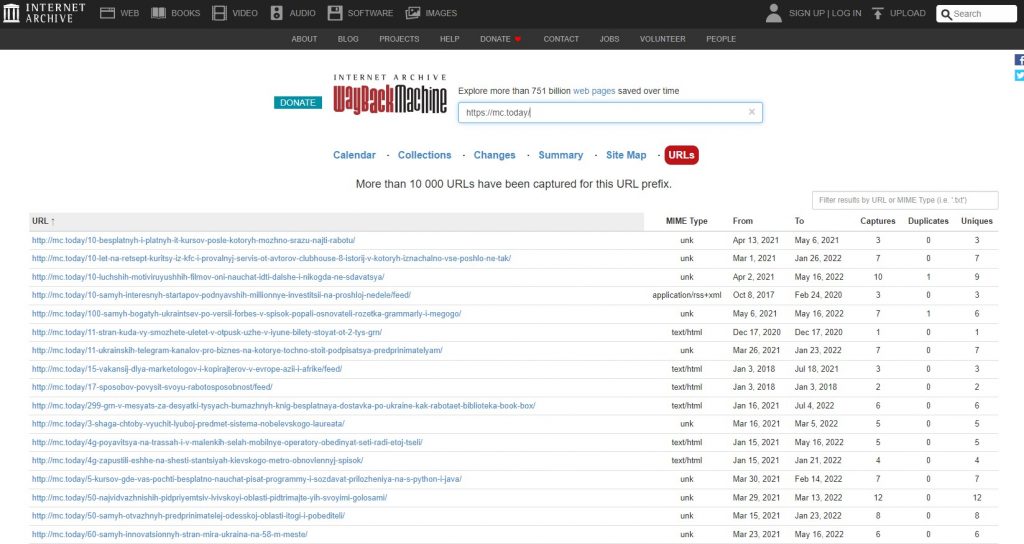
Список усіх заархівованих сторінок сайту
Wayback Machine дозволяє отримати список усіх заархівованих сторінок сайту. Для цього потрібно ввести в адресному рядку https://web.archive.org/web/*/[URL]/* . На прикладі нашого сайту видно, що архів видав понад десять тисяч посилань, які можна додатково відфільтрувати за ключовими словами та типом.
Як заборонити додавання сайту до веб-архіву
Не всі власники сайтів хочуть, щоб їхні проекти зберігалися у Wayback Machine. Одні побоюються за свій унікальний контент і не хочуть, щоб хтось використовував його у разі видалення сайту. І ці побоювання справді мають під собою ґрунт. Адже в Мережі повно інструкцій, як без особливих витрат поповнити зміст свого сайту корисним контентом із закритих ресурсів.
Інші збираються продавати домен і не зацікавлені, щоб його зміст пов’язували з новими власниками, чи хочуть таким чином захистити особисту інформацію. У будь-якому випадку додавання сайту до архіву можна заборонити.
Найпростіше це зробити через зміну параметрів файлу robots.txt, який блокує доступ до сайту для пошукових роботів. Внаслідок заборони роботи перестануть сканувати сайт, і нові сторінки з нього архівуватися не будуть. Але зібрана раніше інформація все ще залишиться доступною.
Щоб її видалити, достатньо надіслати запит на пошту info@archive.org . Важливо також, щоб листа було надіслано з пошти в домені вашого сайту. Зазвичай питання вирішується протягом трьох днів, і сайт повністю зникає з архіву. Аналогічно ресурс можна відновити в Wayback Machine.
Отже, веб-архів – це безкоштовний проект, який має на меті зібрати і зберегти весь доступний в інтернеті контент. За допомогою інструменту Wayback Machine в архіві інтернету легко знайти копії цікавого вам сайту за обрану дату, що може стати в нагоді в різних ситуаціях. Наприклад, дозволить відновити сторінки після атаки хакерів, проаналізувати зміни проекту або просто дізнатися про що улюблений сайт писав 20 років тому.









Повідомити про помилку
Текст, який буде надіслано нашим редакторам: