Что такое big data, где они применяются и как помогают нарисовать портрет клиентов
Мы живем в информационную эпоху, когда почти все наши действия оставляют цифровой след. Это означает, что объемы информации настолько велики и разнообразны, что их нельзя обработать традиционными способами. Большие данные анализируют и используют с помощью технологий big data.
 Modern web network and internet telecommunication technology, big data storage and cloud computing computer service business concept: server room interior in datacenter in blue light
Modern web network and internet telecommunication technology, big data storage and cloud computing computer service business concept: server room interior in datacenter in blue lightРедакция MC.today разобралась, что такое big data и как использовать технологии больших данных.
Что такое big data
Big data ![]()
![]() (англ. «большие данные». – Прим. ред.) – это сложные наборы разной структурированной и неупорядоченной информации больших объемов. Массив информации в мире постоянно растет, ведь мы создаем данные, когда пользуемся интернетом, особенно интернетом вещей
(англ. «большие данные». – Прим. ред.) – это сложные наборы разной структурированной и неупорядоченной информации больших объемов. Массив информации в мире постоянно растет, ведь мы создаем данные, когда пользуемся интернетом, особенно интернетом вещей ![]()
![]() (англ. internet of things, IoT – сеть физических устройств, которые автоматически обмениваются данными с компьютерными системами. – Прим. ред.), социальными
(англ. internet of things, IoT – сеть физических устройств, которые автоматически обмениваются данными с компьютерными системами. – Прим. ред.), социальными
Поэтому big data еще называют инструменты, которые позволяют обработать большие данные так, чтобы использовать их для конкретных целей и задач. То есть в зависимости от контекста для информационных технологий это понятие означает:
- большие объемы цифровых данных;
- набор аналитических инструментов и методов для их обработки.
Отличия от традиционной аналитики
Большие данные не просто большие, они огромные, и их объемы растут экспоненциально ![]()
![]() (геометрический рост, который означает, что чем больше величина, тем быстрее она растет. – Прим. ред.). Поэтому инструменты традиционной аналитики, в которых используется человеческий труд и настольные компьютеры, не могут справиться с анализом и обработкой big data.
(геометрический рост, который означает, что чем больше величина, тем быстрее она растет. – Прим. ред.). Поэтому инструменты традиционной аналитики, в которых используется человеческий труд и настольные компьютеры, не могут справиться с анализом и обработкой big data.
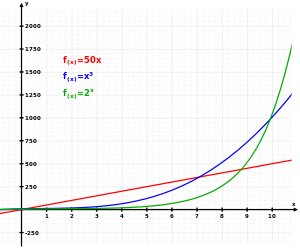
График показывает, как экспоненциальный рост (зеленая кривая) превосходит линейный (красная кривая) и кубический (синяя кривая) рост. Источник: Wikipedia
Вот главные отличия big data от традиционной аналитики.
| Big data | Традиционная аналитика |
| Данные анализируют в реальном времени, по мере их поступления. | Данные сначала собирают, систематизируют, а потом анализируют. |
| Полный поток данных обрабатывают в исходном виде. | Перед тем как обработать данные, их редактируют и сортируют. |
| Анализируют весь массив доступных видов информации. | Данные анализируют поэтапно, по мере поступления небольших массивов информации. |
| Анализ заключается в поиске зависимостей и причинно-следственных связей в потоке информации. Гипотеза выдвигается после анализа. | Анализ предполагает проверку гипотезы на доступных пакетах данных. |
| Анализ происходит автоматически, применяют машинное обучение |
Аналитическую работу делает человек – он ориентируется на поставленные задачи. Традиционная аналитика проверяет результаты использования данных. |
Задачи и функции big data
Понятие big data закрывает три основные задачи – три V ![]()
![]() (V – заглавная буква английских слов, которые означают «объем», «скорость» и «разнообразие», – Прим. ред.):
(V – заглавная буква английских слов, которые означают «объем», «скорость» и «разнообразие», – Прим. ред.):
- Volume

 (англ. «объем». – Прим. ред.). К 2021 году мировой объем данных должен был достигнуть 79 ЗБ . Уже в 2025 году цифра увеличится более чем вдвое, и так по нарастающей экспоненте.
(англ. «объем». – Прим. ред.). К 2021 году мировой объем данных должен был достигнуть 79 ЗБ . Уже в 2025 году цифра увеличится более чем вдвое, и так по нарастающей экспоненте.
Быстрому росту трафика данных способствует интернет вещей – объем информации о соединениях физического и цифрового мира в 2019 году достиг 13,6 зеттабайта. К 2025 году этот трафик данных превысит 79 зеттабайт. Поэтому первая задача big data – хранить большие объемы информации и расширять сети дата-центров, в которых информация собирается, накапливается, хранится и анализируется.
- Velocity (англ. «скорость». – Прим. ред.). Big data учитывает, как быстро накапливаются и обрабатываются новые данные. Задача технологии – успевать за их скоростью прироста и обрабатывать их с учетом экспонентных темпов изменения и всплесков активности.
- Variety (англ. «разнообразие». – Прим. ред.). Big data обрабатывает разные типы структурированной и неструктурированной информации: цифры и данные клиентских баз, видеоконтент, аудиофайлы, текстовые сообщения и так далее. Задача – вычленить из разных потоков определенные закономерности, которые можно использовать, например, для продвижения продуктов, услуг и товаров.
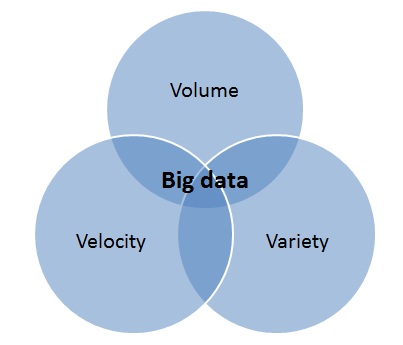
Источник: bigdataldn.com
Часто big data решает еще две задачи:
- Variability (англ. «изменчивость». – Прим. ред.). Потоки данных имеют пики и спады, зависят от сезонности, в них есть периодичность. Всплесками неструктурированной информации сложно управлять, поэтому и нужны мощные технологии для обработки.
- Value (англ. «значение, ценность». – Прим. ред.). Информация, которая поступает из разных систем, различается степенью сложности обработки. Задача big data – структурировать информацию, которая поступает из социальных сетей, локационных систем, транзакционных операций и так далее, по степени ее важности.
Вот основные задачи и функции big data.
| Задачи | Функции |
| Хранить большие объемы разной информации и управлять ими. | Использовать массивы необработанных данных. |
| Структурировать разнообразную информацию и выявлять закономерности. | Data mining |
| Быстрая аналитика и прогнозы в реальном времени. | Machine learning |
Технологии big data
К технологиям больших данных сейчас относят решения, которые позволяют обработать сверхбольшие массивы информации. Традиционно выделяют четыре технологии big data:
- NoSQL (англ. not only SQL (structured query language) – не только язык структурированных запросов. – Прим. ред.) – база данных, которая хранит и добывает информацию не по традиционному логическому подходу. В отличие от реляционных (англ. relation – «отношение». – Прим. ред.) баз данных, здесь не строятся таблицы нормализованных наборов стандартных отношений. Технологию начали использовать еще в 1960-х годах, но популярной она стала с запуском компаний Web 2.0: Facebook, Google, Amazon. Большинство NoSQL-технологий за миллисекунды согласовывают данные по «случайному» принципу и используют низкоуровневые запросы. Часто применяют такие NoSQL-решения:
- MongoDB – кросс-платформенная документоориентированная система управления базами данных с поддержкой JSON и динамических схем;
- Apache Cassandra – масштабируемая база данных, которая ориентирована на отказоустойчивость;
- HBase – масштабируемая распределенная база данных с поддержкой структурированного хранения данных большого объема и так далее.
- MapReduce. Технологию придумал Google, но сейчас это общий термин, который используют для определения модели программирования. В этом программном каркасе распределенную параллельную обработку больших массивов данных проводят на обычных недорогих компьютерах. Программа MapReduce включает функции:
- Map (англ. – «карта». – Прим. ред.), которая обрабатывает пары ключ/значения и генерирует набор промежуточных пар ключ/значения;
- Reduce (англ. «уменьшать», «сокращать». – Прим. ред.), которая сводит вместе все промежуточные значения, связанные с одним и тем же промежуточным ключом.
Библиотеки MapReduce используют для разных языков программирования, самая популярная имплементация – Apache Hadoop.
- Apache Hadoop. Свободная программная платформа и каркас на модели программирования MapReduce, в которой организовано распределенное хранение и обработка наборов больших данных. Задачи делятся на мелкие обособленные фрагменты, каждый из которых может быть запущен на отдельном узле кластера серийных компьютеров. Такая обособленность позволяет автоматически обрабатывать информацию, когда аппаратное обеспечение выходит из строя. Среди программного обеспечения, связанного с Hadoop, выделяют:
- Apache Ambari – инструмент управления и мониторинга Hadoop кластеров;
- Apache Avro – система сериализации данных;
- Apache Hive – инфраструктура хранилища данных, которая обеспечивает их агрегацию;
- Apache Pig – высокоуровневый язык потоков данных и программный каркас для параллельных вычислений;
- Apache Spark – высокопроизводительный двигатель для обработки данных, хранящихся в кластере Hadoop и так далее.
- Язык программирования R. Применяют в статистических вычислениях, для анализа и отображения данных в графическом виде. Язык используют в статистическом анализе, включая линейную и нелинейную регрессию, классические статистические тесты, в анализе временных рядов (серий), кластерном анализе и так далее.
Методики анализа и обработки
Big data – это сверхбольшие объемы информации, которые не имеют смысла до их аналитической обработки. Big data можно использовать только после качественного анализа. Методики обработки больших данных постоянно обновляются, сейчас применяют такие:
- классификация – нужна, чтобы предсказать поведение клиента в конкретном сегменте;
- кластерный анализ – выявляет общие признаки, на основании чего классифицирует данные в группы;
- краудсорсинг (англ. crowdsourcing: crowd – «толпа», sourcing – «использование ресурсов». – Прим. ред.) – сбор разнообразной информации из большого количества источников;
- добыча данных (англ. data mining. – Прим. ред.) – выявляет неизвестные, но полезные сведения, которые помогут принять правильное решение;
- машинное обучение (англ. machine learning. – Прим. ред.) – создает самообучающиеся нейронные сети, которые быстро и все качественнее обрабатывают информацию;
- обучение без учителя (англ. unsupervised learning. – Прим. ред.) – способ машинного обучения, который позволяет системе спонтанно решать поставленные задачи без участия человека; его используют, чтобы выявить скрытые функциональные связи в данных;
- обработка сигналов (англ. signal processing. – Прим. ред.) – исследует цифровые сигналы, которые меняются, чтобы распознать их на фоне информационного шума и проанализировать;
- смешение и интеграция – неструктурированные данные переводят в единый формат;
- визуализация – результаты анализа представляют в виде диаграмм и анимации.
Сферы использования
Технологии и методики big data используют крупные корпорации – IBM, Google, Facebook, Visa, Master Card и государственные органы. Например, Национальное агентство по вопросам противодействия коррупции Украины проверяет, соответствует ли уровень жизни чиновников их задекларированным доходам, а Министерство финансов Украины – позволяют ли доходы граждан претендовать им на социальные выплаты.
Сферы использования big data разнообразны и постоянно расширяются. Вот приблизительный и неочевидный перечень сфер, где используют большие данные:
- Финансы. Потоки денег – это цифровая информация, которую анализируют банки, правоохранительные органы и разные финансовые учреждения. В современном мире все сложнее уклоняться от налогов или скрыть кредитную историю.
- Маркетинг и реклама. Big data позволяет предсказать спрос на продукцию на основе обработанных потоков данных из интернета, датчиков интернета вещей, по транзакционным операциям, активности в социальных сетях и так далее.
- Здравоохранение. В условиях пандемии раскрывается все больше персональной информации. Мировая статистика распространения болезни формируется по технологиям big data, что позволяет отслеживать, как болезнь распространяется, и прогнозировать эпидемические всплески, рассчитывать ресурсы для борьбы с вирусом.
- Предупреждение природных и техногенных катастроф. По методикам big data обрабатывают неструктурированные показания разных датчиков, что позволяет определить дату и место возможного катаклизма.
Преимущества технологии big data
В наше время информация – это главный ресурс, потому преимущества аналитической обработки огромных массивов данных очевидны:
- Выбор оптимального бизнес-подхода – на основе обоснованных больших данных легче принимать правильные решения.
- Скорость, с которой принимают решения. Потоки информации анализируются в реальном времени, что влияет на то, как быстро принимают и корректируют решения так, чтобы они привели к нужному результату.
- Анализ легко применять на практике. Чем больше данных доступно, тем легче спрогнозировать поведение нужной аудитории и выходить к клиенту в самый подходящий момент – когда человек сам ищет ваш продукт.
- Вычленение и прогноз закономерностей. Технологии big data в реальном времени создают приближенные к реальности статистические модели, которые показывают неочевидные закономерности, что облегчает работу маркетологов. Например, всплеск обсуждений какой-то темы, сезонные праздники могут увеличить спрос на конкретные товары.
- Математически правильные метрики. Анализ больших данных способен конкретно ответить и доказать, почему все происходит именно так, чего ждать в будущем и что делать, чтобы получить нужный результат.
Популярные сервисы big data
Сервисы big data – это инструменты, которые обрабатывают большие потоки данных и строят на основе анализа разнообразной информации модели, гипотезы и прогнозы. Некоторые сервисы занимаются сбором больших данных сами. Платформы для обработки больших данных можно настроить самостоятельно, а можно получить уже готовую аналитику от владельцев big data, например, мобильных операторов.
Популярные сервисы big data:
- Google Cloud Dataproc. Сервис от Google для запуска заданий Apache Hadoop и Spark, который используют для обработки больших данных и машинного обучения. Это управляемая служба, поэтому ее можно настроить без системного администратора. Сервис интегрирован с другими облачными сервисами Google, включая Cloud Storage, BigQuery и Cloud Bigtable, из-за чего проще вносить и извлекать данные.
- Amazon Elastic MapReduce. Это облачная платформа больших данных, которая обрабатывает распределенные данные в большом масштабе, работает с интерактивными запросами SQL и запускает машинное обучение при помощи платформ аналитики с открытым исходным кодом, например Apache Spark, Apache Hive и Presto. Сервис обрабатывает большие данные и дает прогноз «что, если» с помощью статистических алгоритмов и моделей, которые обнаруживают скрытые закономерности, взаимосвязи, рыночные тенденции и раскрывают предпочтения клиентов.
- Big-data-решения от «Киевстара». Украинский мобильный оператор запустил клиентский сервис для бизнеса. Big-data-аналитику проводит команда, а клиент получает уже готовую картину: портрет клиента, данные о look-alike-аудитории (пользователи, которые похожи на исходную аудиторию. – Прим. ред.), рекомендации таргетированных и триггерных рассылок, настройки рекламных кампаний, прогнозы платежеспособности клиентов.
- Big data Scoring от Vodafone. Этот оператор использует big data, чтобы оценить рисковость клиентов и их склонность к покупкам. Сервис разработан для компаний и ФЛП (физлиц-предпринимателей. – Прим. ред.), которые работают в финансовом или страховом секторе, ритейле. По большим данным Vodafone проводит кредитный скоринг (от англ. score – «балл» – классификация заемщиков на группы для оценки их кредитоспособности и уровня кредитного риска. – Прим. ред.), выявляет мошеннические действия, оценивает склонность к покупке продуктов, прогнозирует спрос, оценивает риск наступления страхового случая, строит модели оттока клиентов, определяет склонность к повторному целевому событию и так далее.
- Big data от lifecell business. Услуга аналогична тем, которые предлагают другие мобильные операторы, только анализируют big data абонентов lifecell. Мобильный оператор использует данные абонентов для скоринга, антифрода (повышение уровня безопасности клиентов. – Прим. ред.), геоаналитики (анализ трафика и места под открытие новых объектов. – Прим. ред.), таргетированных (от англ. targeted – целевой. – Прим. ред.) коммуникаций.
Выводы
Даже если вы знаете, что такое big data, уберечь свои данные практически невозможно. Все, что вы делаете, сохраняется в интернете и становится частью больших данных, которые используют повсеместно. С другой стороны, информационный след каждого помогает человечеству взаимодействовать: продавать и покупать товары, переводить и получать деньги, прогнозировать катаклизмы и рассчитывать ресурсы для борьбы с их последствиями.
Перспективы big data огромны. С каждым годом в мире накапливается все больше информации. Структурировать и анализировать эти массивы помогают машины.
Технологии big data зависят от объема, скорости и разнообразия потоков информации. Задачи аналитики big data – вычленить и спрогнозировать закономерности на основе неструктурированных данных разных видов, огромные объемы которых поступают из разных источников в доли миллисекунды.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: